Pushing Dynamics Model
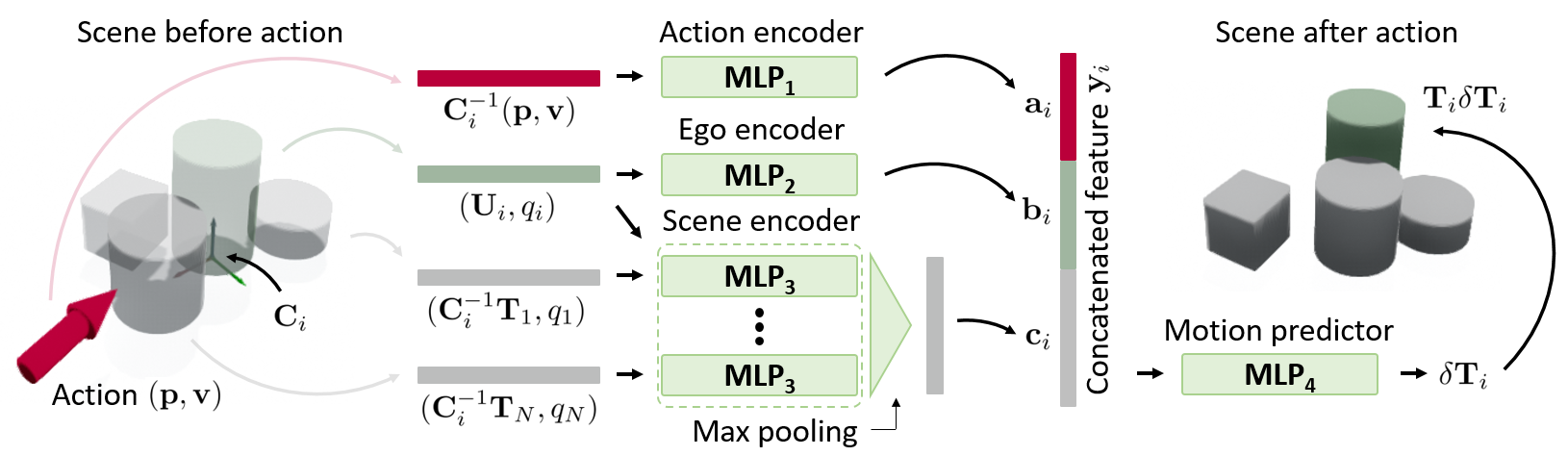
SE(2)-Equivariant Pushing Dynamics Model
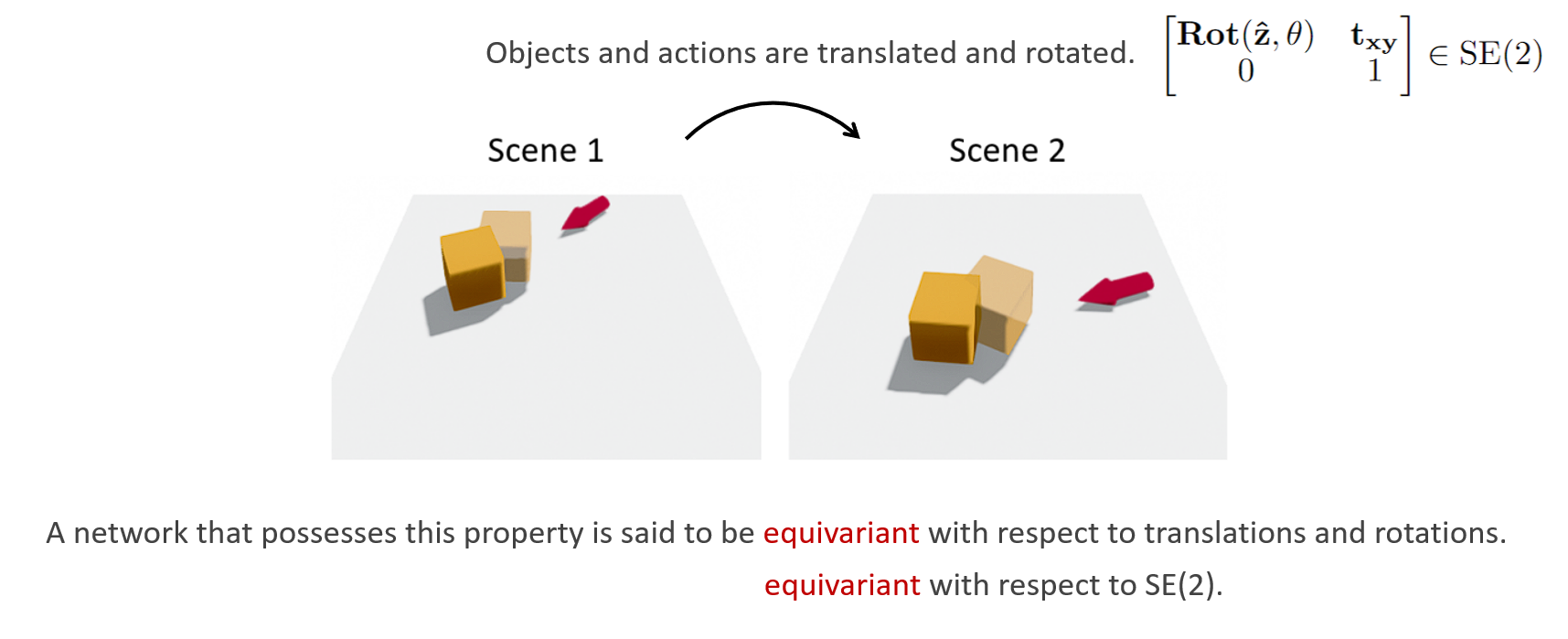
Suppose a pushing dynamics model is trained with an experience where a robot pushes a box object into a red arrow direction as shown in the below figure (Scene 1). Consider a new situation where the same box object is located at a different pose and the robot pushes the object in the same relative direction as shown in Scene 2. At an intuitive level, a good model should be able to easily generalize to this type of new situation, where tabletop objects are only translated or rotated along the \(z\)-axis. In more technical terms, the pushing dynamics model needs to be equivariant to the \(\text{SE}(2)\) transformation.
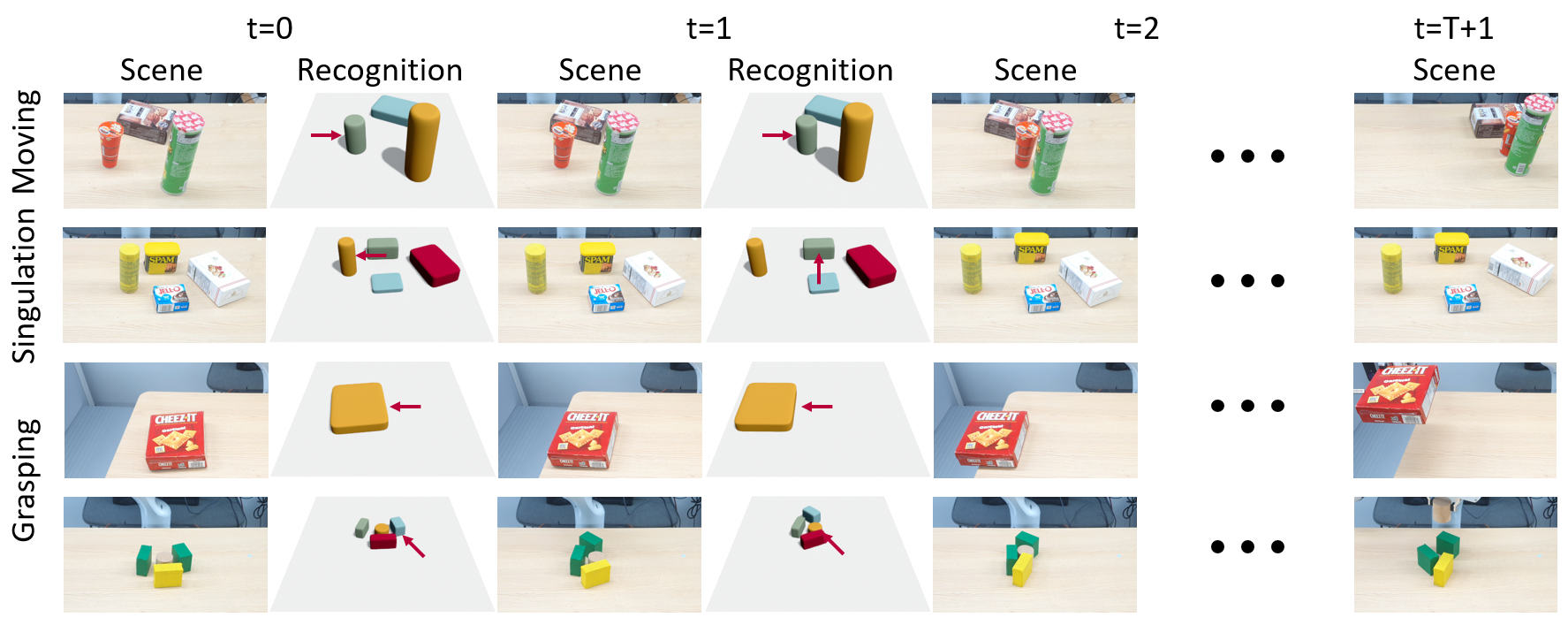
SQPDNet: SuperQuadric Pushing Dynamics Network
The core idea behind making the model \(\text{SE}(2)\)-equivariant is to properly transform the coordinates of the pushing action and the objects' poses as needed. This design naturally captures the symmetry of physical systems and significantly enhances generalization performance. To apply the proposed equivariant pushing dynamics model in environments with only vision data and unseen objects, we use a recognition module capable of identifying the objects' shapes and poses. In this work, we represent 3D object shapes using a shape class called superquadrics. Accordingly, we refer to our superquadric object representation-based pushing dynamics model as the SuperQuadric Pushing Dynamics Network (SQPDNet).